Denoised MDPs: Learning World Models Better Than The World Itself
ICML 2022
TIA does not remove any noise factors, while Denoised MDP correctly identifies all of them.
- Whether they are controllable (Ctrl) or not (Ctrl);
- Whether they are related to rewards (Rew) or not (Rew).
Information in this RoboDesk environment can be categorized as following:

TIA fails to identify any noise with imperfect sensor readings. Denoised MDP, however, still learns a good factorization of signal and noise.
Abstract
The ability to separate signal from noise, and reason with clean abstractions, is critical to intelligence. With this ability, humans can efficiently perform real world tasks without considering all possible nuisance factors. How can artificial agents do the same? What kind of information can agents safely discard as noises? In this work, we categorize information out in the wild into four types based on controllability and relation with reward, and formulate useful information as that which is both controllable and reward-relevant.
This framework clarifies the kinds information removed by various prior work on representation learning in reinforcement learning (RL), and leads to our proposed approach of learning a Denoised MDP that explicitly factors out certain noise distractors. Extensive experiments on variants of DeepMind Control Suite and RoboDesk demonstrate superior performance of our denoised world model over using raw observations alone, and over prior works, across policy optimization control tasks as well as the non-control task of joint position regression.
Four Types of Information in the Wild
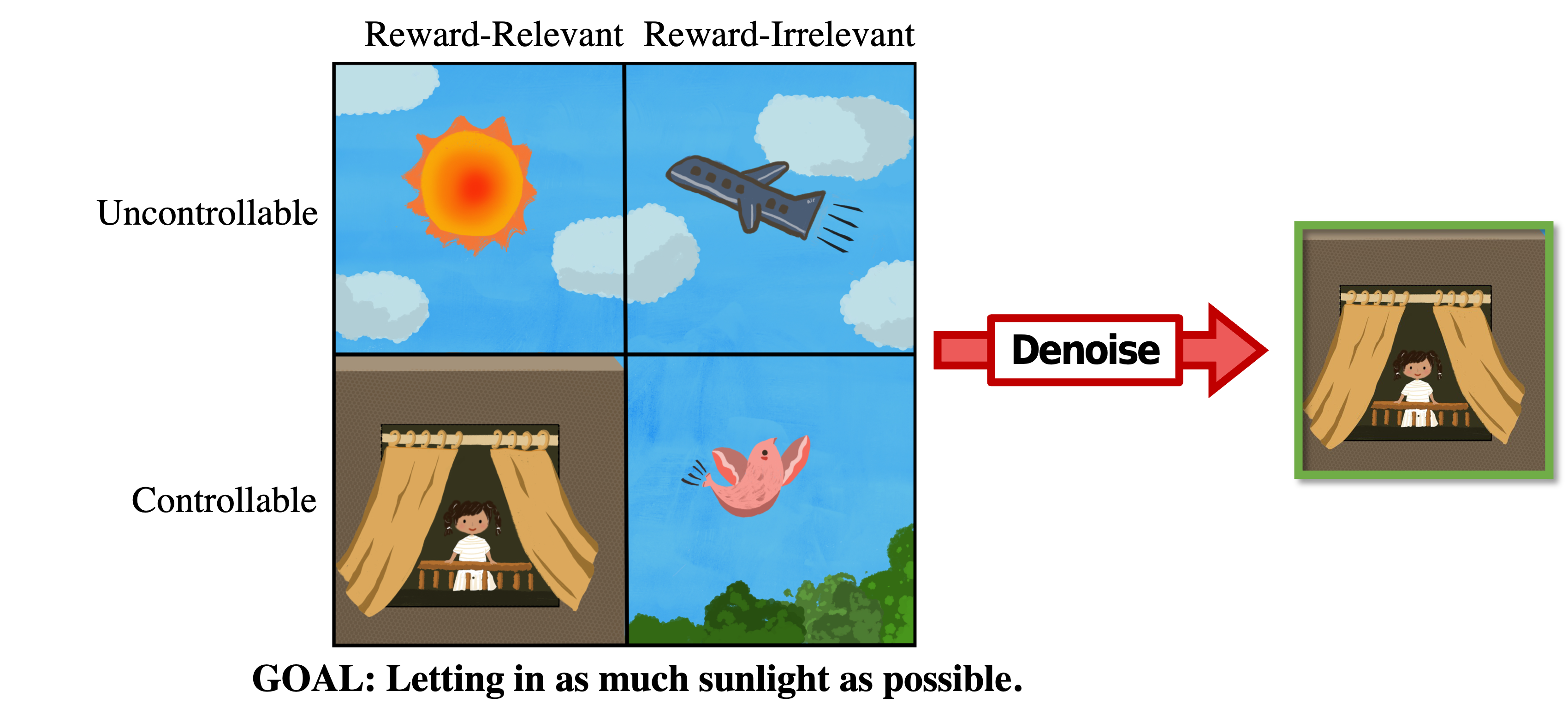
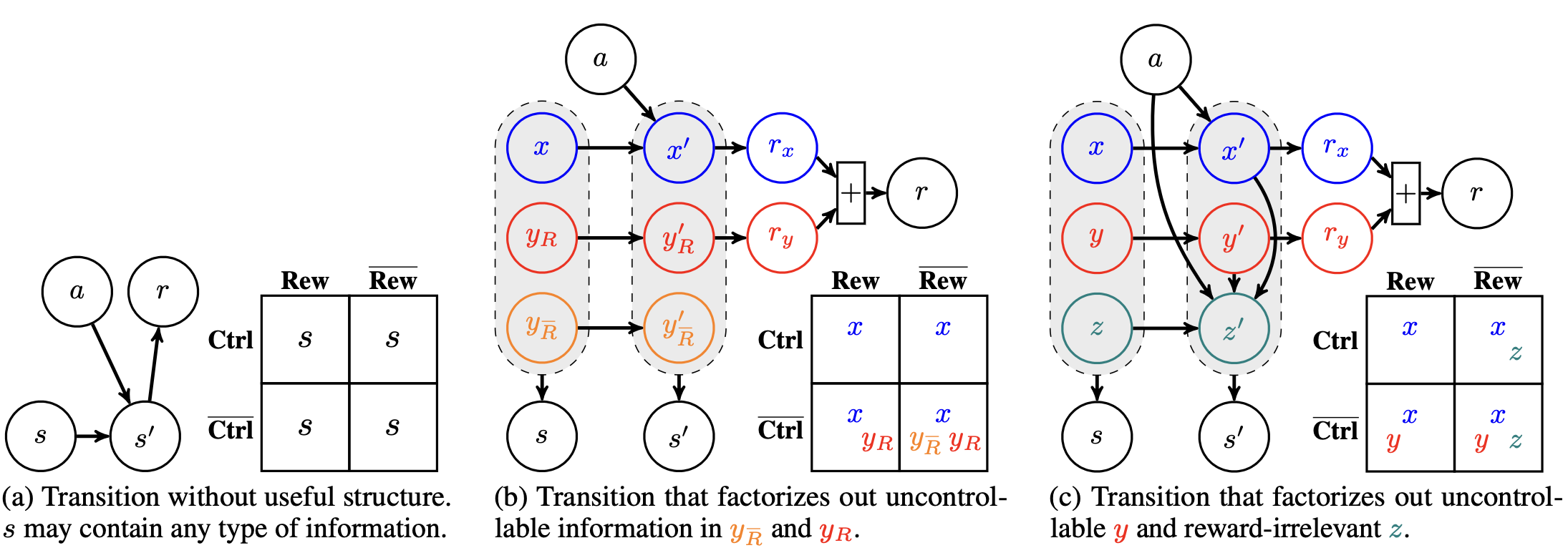
Denoised MDP
Signal-Noise Factorization
TIA does not remove any noise factors, while Denoised MDP correctly identifies all of them.
- Whether they are controllable (Ctrl) or not (Ctrl);
- Whether they are related to rewards (Rew) or not (Rew).
Information in this RoboDesk environment can be categorized as following:
TIA noise latent still captures some robot move ment (see moving ground texture). Denoised MDP correctly learns a collapsed noise latent space for this noiseless environment.
Both TIA and Denoised MDP correctly disentangle signal and noise, showing static background in Signal videos, and (mostly) static robot in Noise videos.
TIA wrongly models robot position as noise and background as signal. Denoised MDP signal latent space correctly contains only robot and target positons.
TIA fails to identify any noise with imperfect sensor readings. Denoised MDP, however, still learns a good factorization of signal and noise.
TIA signal latent fails to ignore camera movements. Denoised MDP correctly finds a signal latent of only the robot position, and a noise latent of only the camera and background.

|
PaperICML 2022. arXiv 2206.15477. CitationTongzhou Wang, Simon S. Du, Antonio Torralba, Phillip Isola, Amy Zhang, Yuandong Tian. "Denoised MDPs: Learning World Models Better Than The World Itself" International Conference on Machine Learning (ICML). 2022. Code: [GitHub] |
bibtex entry
@inproceedings{tongzhouw2022denoisedmdps,
title={Denoised MDPs: Learning World Models Better Than The World Itself},
author={Wang, Tongzhou and Du, Simon S. and Torralba, Antonio and Isola, Phillip and Zhang, Amy and Tian, Yuandong},
booktitle={International Conference on Machine Learning},
organization={PMLR},
year={2022}
}
Acknowledgements
We thank Jiaxi Chen for the beautiful introduction example illustration. We thank Daniel Jiang and Yen-Chen Lin for their helpful comments and suggestions. We are grateful to the following organizations for providing computation resources to this project: IBM's MIT Satori cluster, MIT Supercloud cluster, and Google Cloud Computing with credits gifted by Google to MIT. We are very thankful to Alex Lamb for suggestions and catching our typo in the conditioning of Equation (1).