Dataset Distillation
Tongzhou Wang12 Jun-Yan Zhu2 Antonio Torralba2 Alexei A. Efros3
1Facebook AI Research 2MIT CSAIL 3UC Berkeley
Paper | PyTorch code
The Dataset Distillation Task
Dataset distillation is the task of synthesizing a small dataset such that models trained on it achieve high performance on the original large dataset. A dataset distillation algorithm takes as input a large real dataset to be distilled (training set), and outputs a small synthetic distilled dataset, which is evaluated via testing models trained on this distilled dataset on a separate real dataset (validation/test set). A good small distilled dataset is not only useful in dataset understanding, but has various applications (e.g., continual learning, privacy, neural architecture search, etc.). This task was first introduced in our 2018 paper Dataset Distillation [Wang et al., '18], along with a proposed algorithm using backpropagation through optimization steps. Details of this paper are also presented on this webpage.
In recent years (2019-now), dataset distillation has gained increasing attention in the research community, across many institutes and labs. More papers are now being published each year. These wonderful researches have been constantly improving dataset distillation and exploring its various variants and applications.
Our Dataset Distillation Papers:
- T. Wang, J. Y. Zhu, A. Torralba, A. and A. A. Efros. "Dataset Distillation". 2018.
- G. Cazenavette, T. Wang, A. Torralba, A. A. Efros, J. Y. Zhu. "Dataset Distillation by Matching Training Trajectories". CVPR 2022.
- G. Cazenavette, T. Wang, A. Torralba, A. A. Efros, J. Y. Zhu. "Wearable ImageNet: Synthesizing Tileable Textures via Dataset Distillation". Workshop on Computer Vision for Fashion, Art, and Design at CVPR 2022.
Other Works Related to Dataset Distillation (Partial List):
- [Zhao et al., ICLR 2021]: new method called Dataset Condensation optimizing a gradient-matching surrogate objective.
- [Nguyen et al. NeurIPS 2021]: distillation w.r.t. the infinite-width limit Neural Tangent Kernel.
- [Kim et al., ICML 2022]: reparametrizing distilled dataset via multi-scale patches.
- [Jin et al. ICLR 2022]: distill large-scale graph for graph neural networks.
- [Lee et al., ICML 2022]: careful scheduling of class-wise and class-collective objectives.
- [Such et al., ICML 2020]: training a generator that outputs good synthetic trianing data, with application in Neural Architecture Search.
- [Deng et al., 2022]: new reparametrization that improves distillation via simple backpropagation through optimization steps, with application in continual learning.
Please check out this awesome collection of dataset distillation papers, curated and maintained by Guang Li, Bo Zhao and Tongzhou Wang.
Last updated by Tongzhou Wang on August 7th 2022.
Check out our latest CVPR 2022 work: Project | Paper | PyTorch code
Dataset Distillation
Abstract
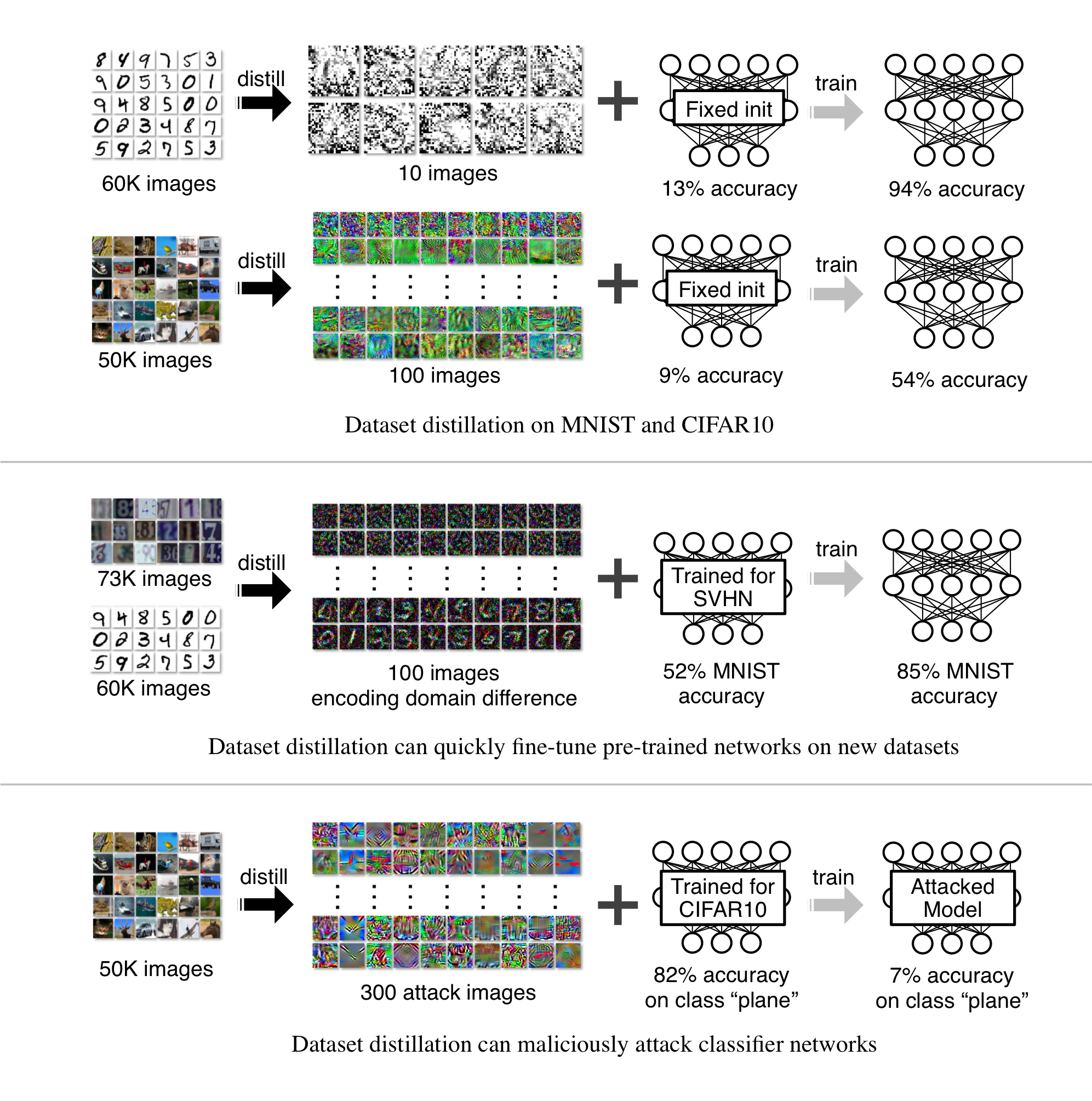
Model distillation aims to distill the knowledge of a complex model into a simpler one. In this paper, we consider an alternative formulation called dataset distillation: we keep the model fixed and instead attempt to distill the knowledge from a large training dataset into a small one. The idea is to synthesize a small number of data points that do not need to come from the correct data distribution, but will, when given to the learning algorithm as training data, approximate the model trained on the original data. For example, we show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few steps of gradient descent, given a fixed network initialization. We evaluate our method in various initialization settings and with different learning objectives. Experiments on multiple datasets show the advantage of our approach compared to alternative methods.

Paper
arxiv 1811.10959, 2018.
Citation
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A. Efros. "Dataset Distillation", arXiv preprint, 2018. Bibtex
Code: GitHub
Experiment Results
Standard devaiations mentioned below are calculated on 200 held-out models.
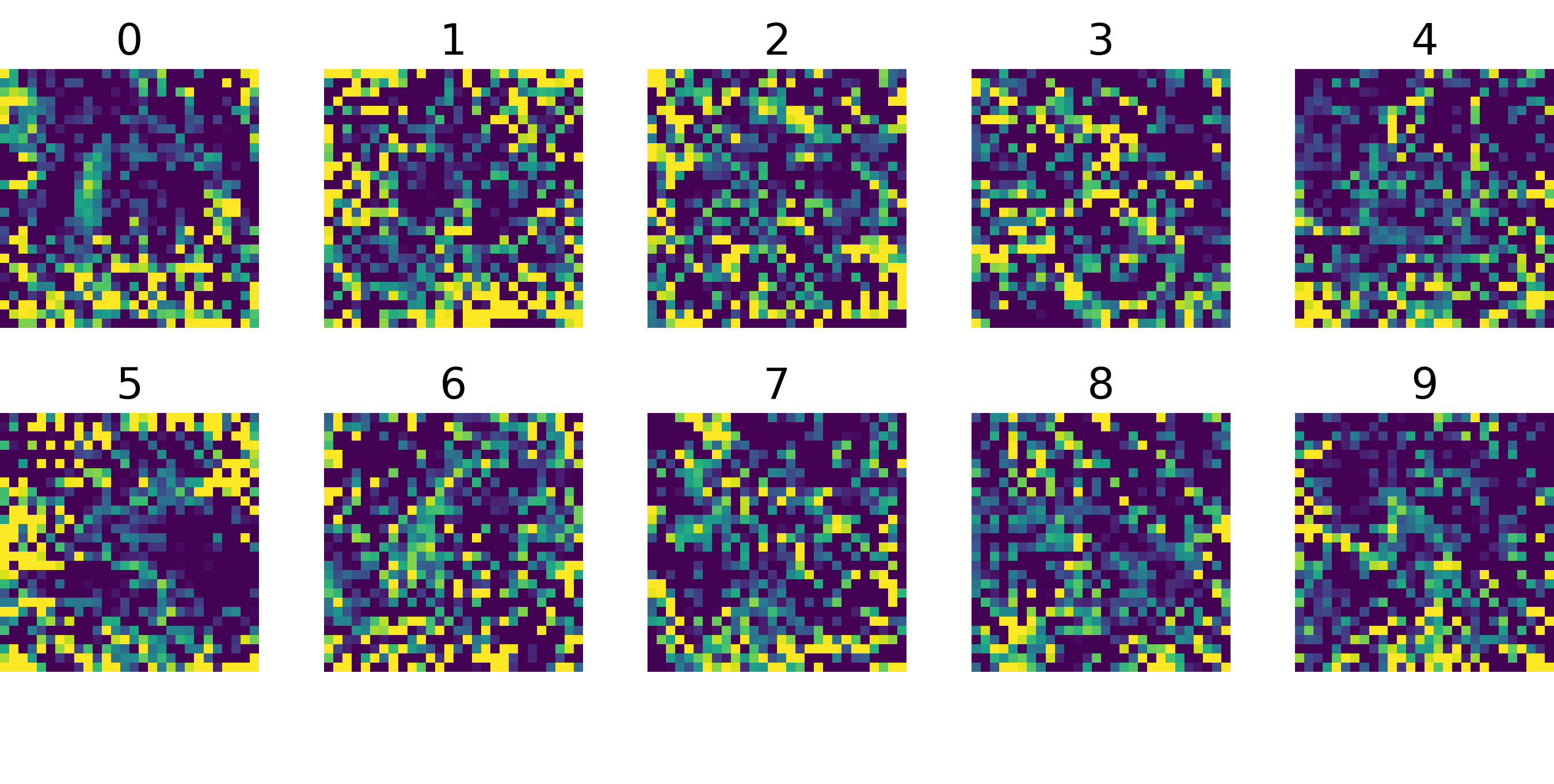
Train networks with a fixed known initialization
MNIST10 images train test accuracy from 12.9% to 93.8% |
CIFAR10100 images train test accuracy from 8.8% to 54.0% |
|

|
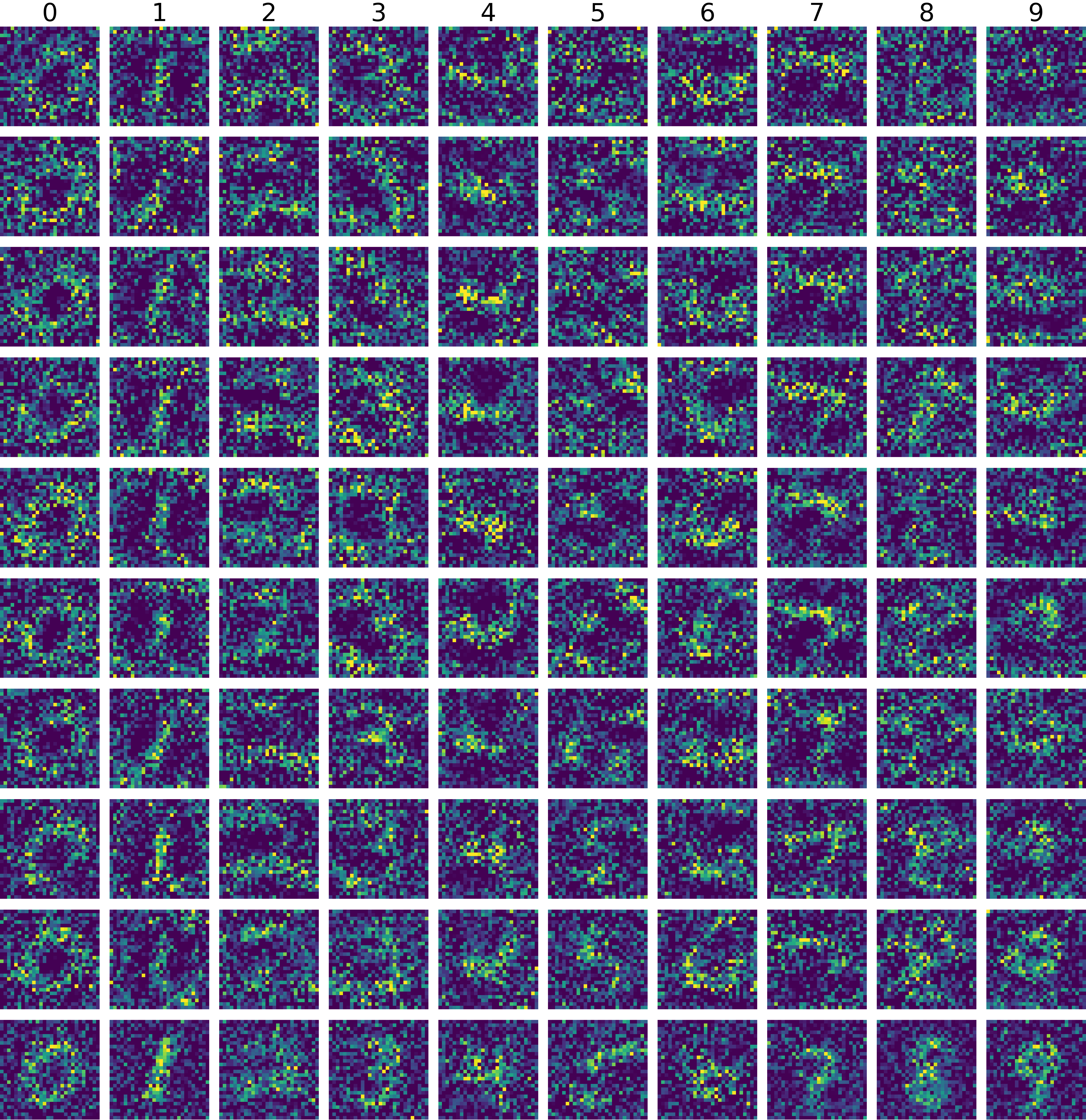
Train networks with unknown random initializations
MNIST100 images train test accuracy to 79.5% ± 8.1% |
CIFAR10100 images train test accuracy to 36.8% ± 1.2% |
|

|
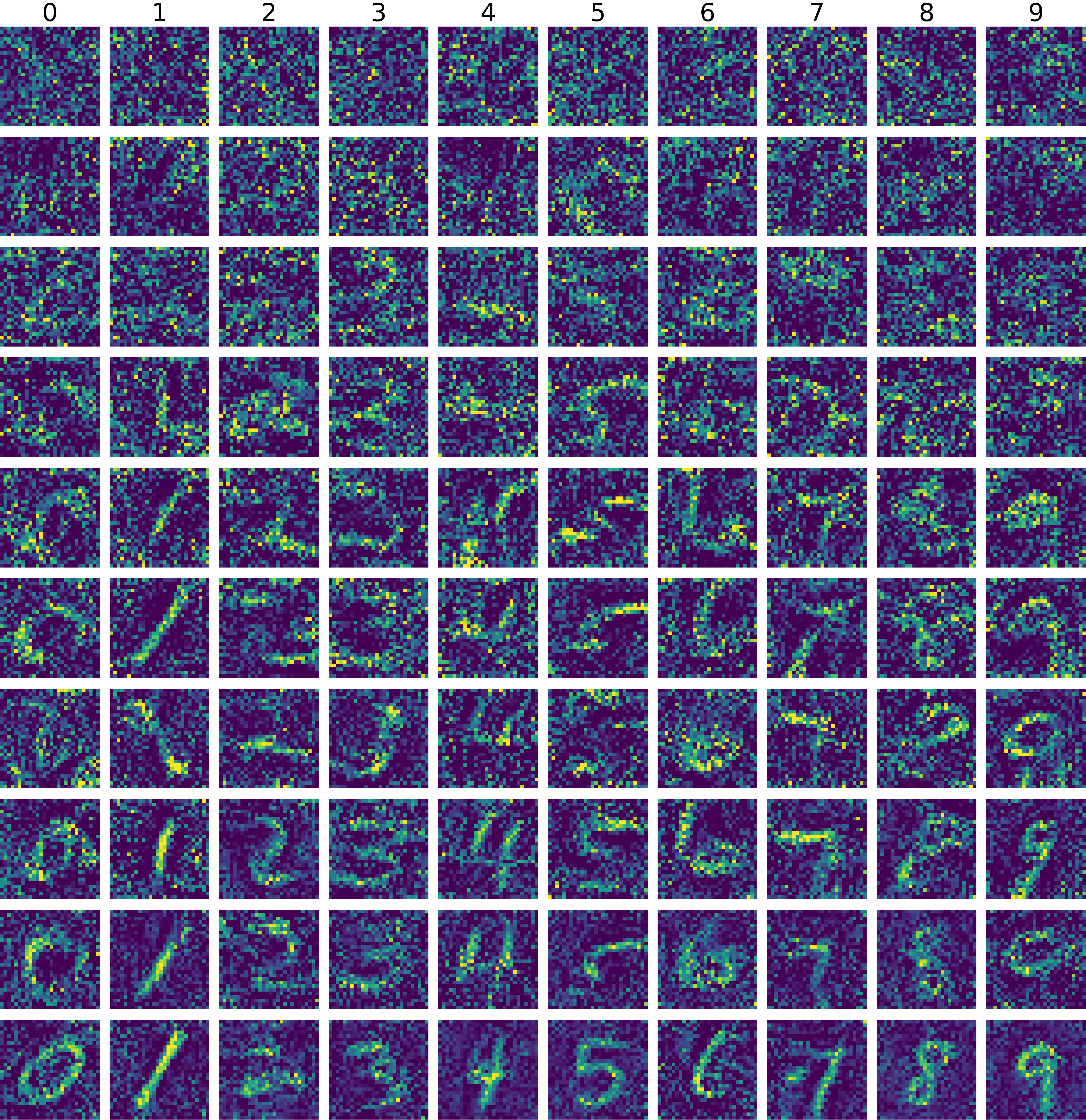
Adapt pre-trained networks with unknown weights to a new dataset
USPS ⟶ MNIST100 images train test accuracy |
SVHN ⟶ MNIST100 images train test accuracy |
|
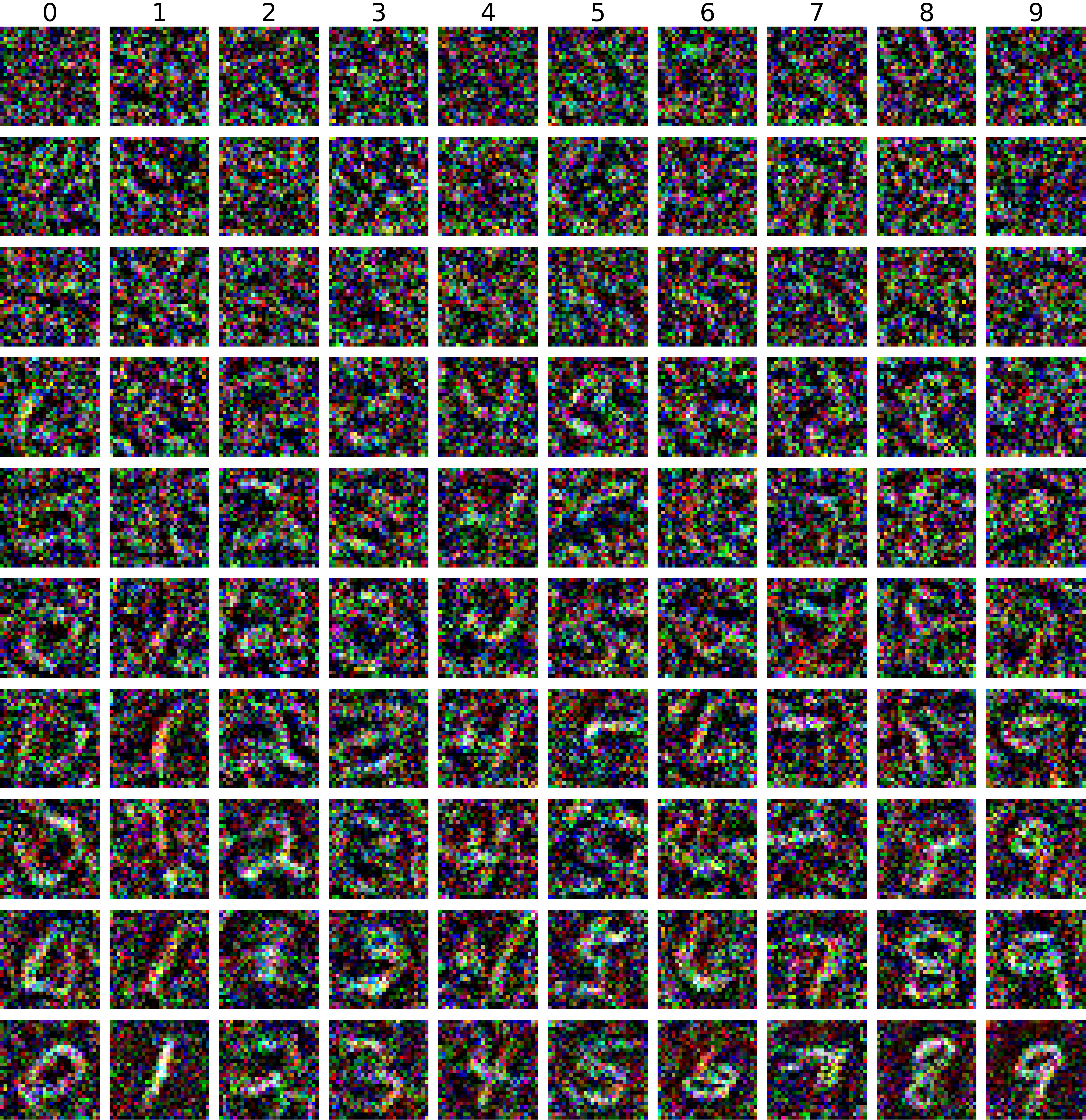
|
Attack well-trained classifiers with unknown weights within 1 gradient step
MNIST: 0 ⟶ 1100 images train classifiers with 98.6% ± 0.5% test accuracy |
CIFAR10: plane ⟶ car100 images train classifiers with 78.2% ± 1.1% test accuracy |
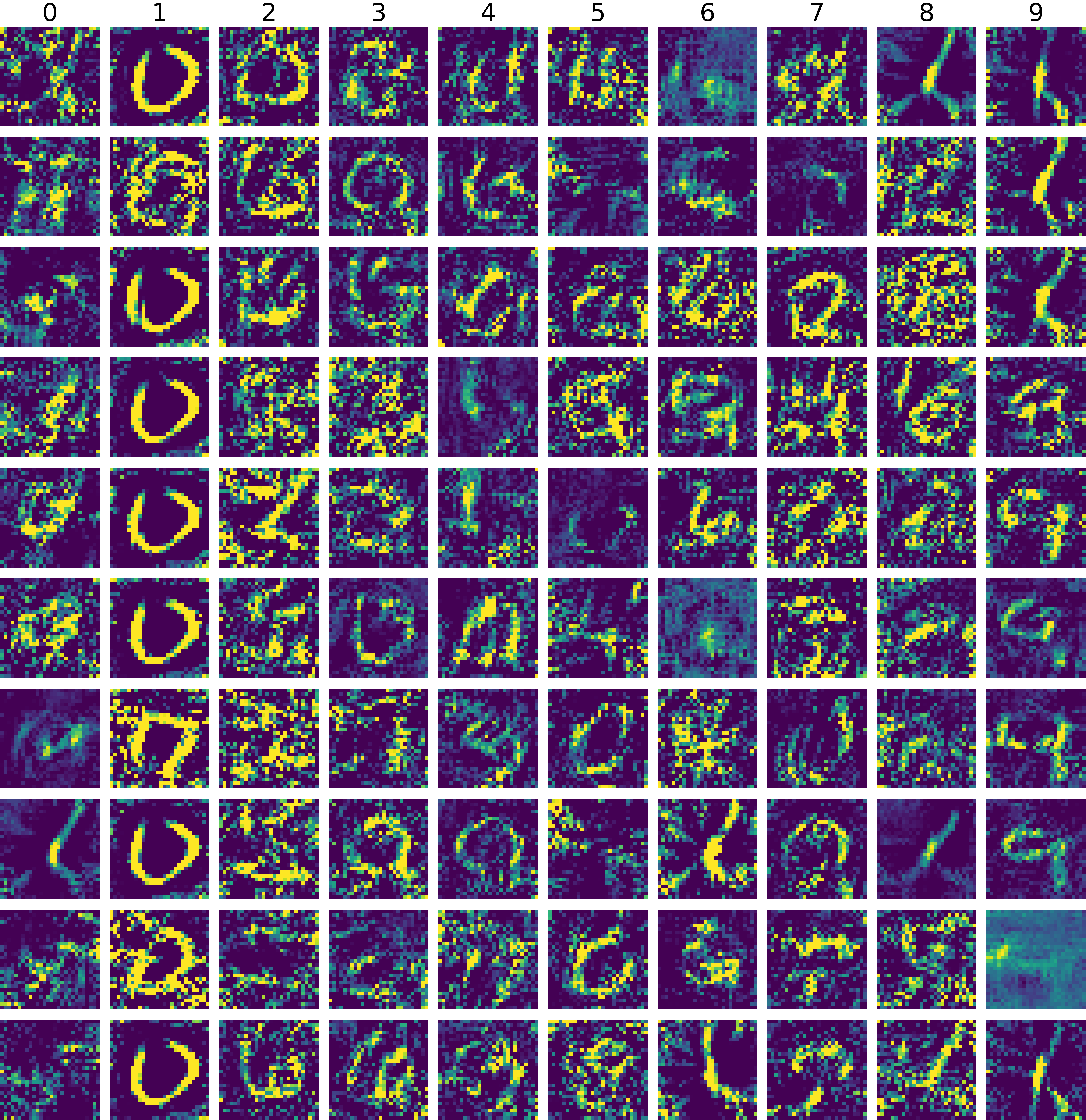
|

|
See our paper for more experiments, including adapting an AlexNet (pre-trained on ImageNet) to PASCAL-POC and CUB-200 with only one image per class.
Related Work
Acknowledgement
This work was supported in part by NSF 1524817 on Advancing Visual Recognition with Feature Visualizations, NSF IIS-1633310, and Berkeley Deep Drive.
